面试中数据库相关问题
数据库面试考点
1. 优化查询的方法?
- 使用索引:尽量避免全表扫描,首先考虑在where,order by,group by涉及的列上建立索引;
- 优化SQL语句:用具体的字段代替‘*’,不要返回用不到的字段;不在索引列做运算或函数;查询尽可能使用limit限制返回的行数;
- 优化数据库对象:优化表的数据类型(使用能正确表示并且最短的数据类型,减少磁盘压力);对表进行拆分(垂直拆分和水平拆分);使用中间表来提高查询速度;
- 硬件优化;
- MYSQL自身的优化:配置文件my.cnf的各项参数进行优化调整,如查询缓冲区的大小,指定最大连接数量;
- 应用优化:使用数据库连接池;使用查询缓存(使用不频繁更新的数据库);
2. 如果有一个特别大的访问量到数据库上, 怎么做优化?
- 优化查询(如上);
- 主从复制,读写分离,负载均衡:通过配置两台( 或多台)数据库的主从关系, 可以将一台数据库服务器的数据更新同步到另一台服务器上。 网站可以利用数据库的这一功能, 实现数据库的读写分离, 从而改善数据库的负载压力。 一个系统的读操作远远多于写操作, 因此写操作发向 master, 读操作发向 slaves 进行操作( 简单的轮循算法来决定使用哪个 slave) 。
- 数据库分表,分区,分库:
- 分区就是把一张表的数据分成多个区块, 这些区块可以在一个磁盘上, 也可以在不同的磁盘上, 分区后, 表面上还是一张表, 但数据散列在多个位置, 这样一来, 多块硬盘同时处理不同的请求, 从而提高磁盘 I/O 读写性能, 实现比较简单。 包括水平分区和垂直分区。
- 分库是根据业务不同把相关的表切分到不同的数据库中, 比如 web、 bbs、 blog 等库。
3. 什么叫做 SQL 注入, 如何防止?
- SQL注入攻击指的是通过构建特殊的输入作为参数传入Web应用程序,而这些输入大都是SQL语法里的一些组合,通过执行SQL语句进而执行攻击者所要的操作,其主要原因是程序没有细致地过滤用户输入的数据,致使非法数据侵入系统。
- 如何防止:
- 严格限制Web应用的数据库的操作权限;
- 永远不要使用动态拼装sql,可以使用参数化的sql或者直接使用存储过程进行数据查询存取;
- 对用户的输入进行校验,可以通过正则表达式,或限制长度;对单引号和双”-“进行转换等。
- 应用的异常信息应该给出尽可能少的提示,最好使用自定义的错误信息对原始错误信息进行包装;
- 不要把机密信息直接存放,加密或者hash掉密码和敏感的信息。
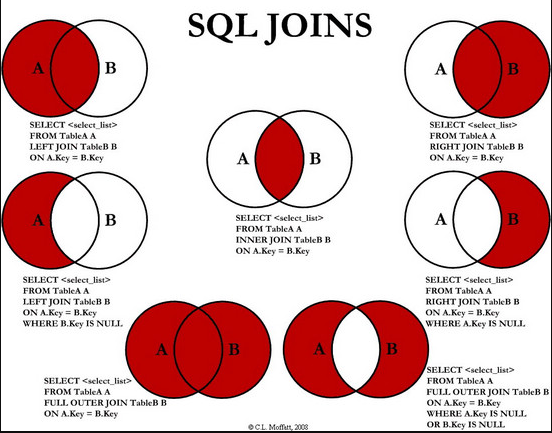
4. 数据库JOIN详解
- 数据库数据:
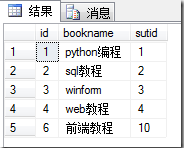
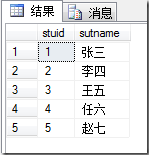
- 内连接:内连接查询操作列出与连接条件匹配的数据行,它使用比较运算符比较被连接列的列值
select * from book as a,stu as b where a.sutid = b.stuid select * from book as a inner join stu as b on a.sutid = b.stuid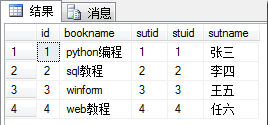
- 外连接:
- 左连接:是以左表为基准,将a.stuid = b.stuid的数据进行连接,然后将左表没有的对应项显示,右表的列为NULL
select * from book as a left join stu as b on a.sutid = b.stuid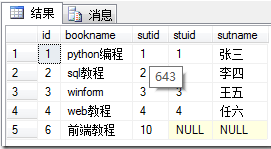
- 右连接:是以右表为基准,将a.stuid = b.stuid的数据进行连接,然以将右表没有的对应项显示,左表的列为NULL
select * from book as a right join stu as b on a.sutid = b.stuid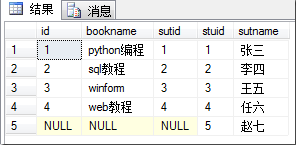
- 全连接:完整外部联接返回左表和右表中的所有行。当某行在另一个表中没有匹配行时,则另一个表的选择列表列包含空值。如果表之间有匹配行,则整个结果集行包含基表的数据值。
select * from book as a full outer join stu as b on a.sutid = b.stuid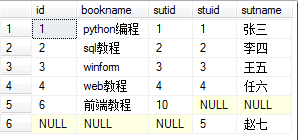
- 左连接:是以左表为基准,将a.stuid = b.stuid的数据进行连接,然后将左表没有的对应项显示,右表的列为NULL
- 交叉连接:交叉联接返回左表中的所有行,左表中的每一行与右表中的所有行组合。交叉联接也称作笛卡尔积。
select * from book as a cross join stu as b order by a.id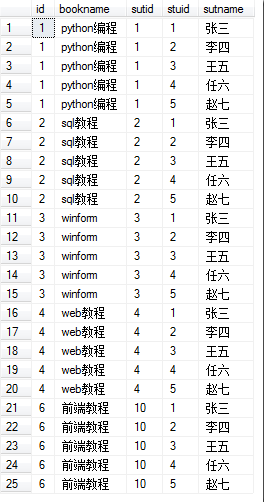
5. 数据库的三级范式
- 1NF:字段不可再分,即原子性;
- 2NF: 满足第二范式( 2NF ) 必须先满足第一范式( 1NF ) 。一个表只能说明一个事物。 非主键属性必须完全依赖于主键属性;
- 3NF:满足第三范式( 3NF ) 必须先满足第二范式( 2NF ) , 每列都与主键有直接关系, 不存在传递依赖。 任何非主属性不依赖于其它非主属性;
6. 数据库事务的四大属性
事务是由一组 SQL 语句组成的逻辑处理单元。 ACID: 原子性(Atomicity) 、 一致性( Consistency) 、 隔离性( Isolation) 、持久性( Durability) 。
- 原子性: 一个事务(transaction)中的所有操作, 要么全部完成, 要么全部不完成,不会结束在中间某个环节。 事务在执行过程中发生错误, 会被 回滚 ( Rollback) 到事务开始前的状态, 就像这个事务从来没有执行过一样;
- 一致性: 在事务开始和完成时, 数据库中的数据都保持一致的状态, 数据的完整性约束没有被破坏。 (事务的执行使得数据库从一种正确状态转换成另一种正确状态) 。 具体来说就是, 比如表与表之间存在外键约束关系, 那么你对数据库进行的修改操作就必需要满足约束条件, 即如果你修改了一张表中的数据, 那你还需要修改与之存在外键约束关系的其他表中对应的数据, 以达到一致性;
- 隔离性: 一个事务的执行不能被其他事务干扰。 为了防止事务操作间的混淆, 必须串行化或序列化请 求, 使得在同一时间仅有一个请求用于同一数据。(在事务正确提交之前,不允许把该事务对数据的任何改变提供给任何其他事务) 。 (事务处理过程中的中间状态对外部是不可见的) 。 隔离性通过锁就可以现;
- 持久性: 一个事务一旦提交, 它对数据库中数据的改变就应该是永久性的, 并不会被回滚;
7. 并发事务带来的问题
- 更新丢失:两个事务 Tl 和 T2 读入同一数据并修改, T2 提交的结果覆盖了 Tl 提交的结果, 导致 Tl 的修改被丢失。
- 脏读:事务 Tl 修改某一数据, 并将其写回磁盘, 事务 T2 读取同一数据后, Tl 由于某种原因被撤销, 这时 Tl 已修改过的数据恢复原值, T2 读到的数据就与数据库中的数据不一致, 则 T2 读到的数据就为“脏” 数据, 即不正确的数据。
- 不可重复读:同样的条件, 你读取过的数据, 再次读取出来发现值不一样;
- 幻读:第 1 次和第 2 次读出来的记录数不一样;
8. 数据库怎么保证数据的一致性
- 事务, 悲观锁, 乐观锁。
- 悲观锁:从数据开始更改时就将数据锁住, 直到更改完成才释放。
- 乐观锁:准备提交所做的修改到数据库的时候才会将数据锁住。
- 如果并发量不大, 可以使用悲观锁解决并发问题;但如果系统的并发量非常大的话,悲观锁定会带来非常大的性能问题,所以我们就要选择乐观锁定的方法.现在大部分应用都应该是乐观锁的。
9. 索引优缺点
- 优点:
- 大大加快数据的检索速度;
- 创建唯一性索引,保证数据库中每一行数据都是唯一的;
- 加速表与表之间的连接;
- 在使用分组和排序进行检索时,可以显著减少时间;
- 缺点:
- 索引需要占用物理空间;
- 对表中数据进行增,删和修改时,也要对索引进行操作,增加了数据维护时间;
10. 索引有哪些?
索引的作用:排列好次序,使得查询时可以快速找到。
- 唯一索引:在表上一个或者多个字段组合建立的索引, 这个或者这些字段的值组合起来在表中不可以重复。
- 非唯一索引:表上一个或者多个字段组合建立的索引, 这个或者这些字段的值组合起来在表中可以重复, 不要求唯一。
- 主键索引(主索引):唯一索引的特定类型,表中创建主键时自动创建的索引 。 一个表只能建立一个主索引。
- 聚集索引:表中记录的物理顺序与键值的索引顺序相同。 一个表只能有一个聚集索引。
- 组合索引:基于多个字段而创建的索引就称为组合索引。
扩展: 聚集索引和非聚集索引的区别? 分别在什么情况下使用?
根本区别是表中记录的物理顺序和索引的排列顺序是否一致。 聚集索引的表中记录的物理顺序与索引的排列顺序一致: 优点是查询速度快, 因为一旦具有第一个索引值的记录被找到, 具有连续索 引值的记录也一定物理的紧跟其后。 缺点是对表进行修改速度较慢, 这是为了保持表中的记录的物理顺序与索引的顺序一致, 而把记录插入到数据页的相应位置, 必须在数据页中进行数据重排, 降低了执行速度。 在插入新记录时数据文件为了维持 B+Tree 的特性而频繁的分裂调整, 十分低效。 区别:聚集索引和非聚集索引都采用了 B+树的结构, 但非聚集索引的叶子层并不与实际的数据页相重叠, 而采用叶子层包含一个指向表中的记录在数据页中的指针的方式。 聚集索引的叶节点就是数据节点, 而非聚集索引的叶节点仍然是索引节点。
11. 数据库索引实现原理
B+Tree 是数据库系统实现索引的首选数据结构。
- MyISAM 索引实现:MyISAM 引擎使用 B+Tree 作为索引结构, 叶节点的 data 域存放的是数据记录 的地址。“非聚集索引”
- InnoDB 索引实现:InnoDB 中, 表数据文件本身就是按 B+Tree 组织的一个索引结构, 这棵树的叶节点data 域保存了完整的数据记录。 这个索引的 key 是数据表的主键, 因此 InnoDB 表数据文件本身就是主索引。“聚集索引”
- InnoDB 要求表必须有主键,如果没有显式提供,自动为表生成一个隐含字段作为主键;
- 在 InnoDB 上采用自增字段做表的主键。非单调的主键会造成在插入新记录时数据文件为了维持 B+Tree 的特性而频繁的分裂调整。
- InnoDB 的辅助索引 data 域存储相应记录主键的值而不是地址,首先检索辅助索引获得主键, 然后用主键到主索引中检索获得记录;MyISAM 中主索引和辅助索引( Secondary key) 在结构上没有任何区别, 只是主索引要求 key 是唯一的, 而辅助索引的 key 可以重复。
12. Mysql 的 B+树索引的优点?
数据库文件很大, 需要存储到磁盘上, 索引的结构组织要尽量减少查找过程中磁盘I/O 的存取次数。
- 高度原因:B+树中的每个结点可以包含大量的关键字, 这样树的深度降低了, 所以任何关键字的查找必须走一条从根结点到叶子结点的路, 所有关键字查询的路径长度相同, 导致每一个数据的查询效率相当,这就意味着查找一个元素只要很少结点从外存磁盘中读入内存, 很快访问到要查找的数据, 减少了磁盘 I/O 的存取次数。
- 磁盘预读原理和局部性原理:将一个节点的大小设为等于一个页, 这样每个节点只需要一次 I/O 就可以完全载入。
13. 建索引的几大原则
- 最左前缀匹配原则:mysql 会一直向右匹配直到遇到范围查询(>、 <、 between、like)就停止匹配, 范围询会导致组合索引半生效。比如 a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引, c 可以用到索引, d 是用不到索引的, 如果建立(a,b,d,c)的索引则都可以用到, a,b,d 的顺序可以任意调整。
- 尽量选择区分度高的字段作为索引;
- 不在索引列做运算或者使用函数;
- 尽量扩展索引, 不要新建索引:比如表中已经有 a 的索引, 现在要加(a,b)的索引, 那么只需要修改原来的索引即可。
- Where 子句中经常使用的字段应该创建索引,分组字段或者排序字段应该创建索引,两个表的连接字段应该创建索引。
14. mysql中Mylsam与InnoDB的区别
- 事务处理:MyISAM 强调的是性能, 查询的速度比 InnoDB 类型更快, 但是不提供事务支持。InnoDB 提供事务支持事务。
- 外键:MyISAM 不支持外键, InnoDB 支持外键;
- 锁:MyISAM 只支持表级锁, InnoDB 支持行级锁和表级锁, 默认是行级锁;
- 全文索引:MyISAM 支持全文索引, InnoDB 不支持全文索引。 innodb 从 mysql5.6 版本开始提供对全文索引的支持。
- 表主键:
- MyISAM: 允许没有主键的表存在。
- InnoDB: 如果没有设定主键, 就会自动生成一个 6 字节的主键(用户不可见)。
- 表的具体行数:MyISAM 内置了一个计数器, count(*)时它直接从计数器中读。InnoDB要扫描一遍整个表来计算有多少行。
15. 一张表,里面有 ID 自 增主键,当 insert 了 1 7 条记录之后,删除了第 1 5,1 6,1 7 条记录,再把 Mysql 重启 ,再 insert 一条记录,这条记录的 ID 是 1 8 还是 1 5 ?
- 如果表的类型是 MyISAM, 那么是 1 8,MyISAM 表会把自 增主键的最大 ID 记录到数据文件里;
- 如果表的类型是 InnoDB, 那么是 1 5。InnoDB 表只是把自 增主键的最大 ID 记录到内存中;
16. 关系型数据库和非关系型数据库的区别
- 非关系型数据库优势:
- 性能:基于键值对的, 可以想象成表中的主键和值的对应关系, 而且不需要经过 SQL 层的解析, 所以性能非常高。
- 可扩展性:同样也是因为基于键值对, 数据之间没有耦合性, 所以非常容易水平扩展。
- 关系型数据库优势:
- 复杂查询:可以用 SQL 语句方便的在一个表以及多个表之间做非常复杂的数据查询。
- 事务支持:使得对于安全性能很高的数据访问要求得以实现。
17. 数据库连接池的原理? 连接池使用什么数据结构实现? 实现连接池?
- 连接池的工作原理:连接池的核心思想是连接的复用, 通过建立一个数据库连接池以及一套连接使用、 分配和管理策略, 使得该连接池中的连接可以得到高效, 安全的复用, 避免了数据库连接频繁建立和关闭的开销。 工作原理由三部分组成,分别为连接池的建立, 连接池中连接的使用管理, 连接池的关闭。
- 优点:
- 减少连接的创建时间;
- 更快的系统响应速度;
- 统一的连接管理;
18. 服务器与服务器之间传输文件夹下的文件, 一个文件夹下有 1 0 个文件, 另一个文件夹下有 1 00 个文件, 两个文件夹大小相等, 问, 哪个传输更快?
1 0 个文件更快。
- 建立连接数更少, 建立连接的开销比传输文件的开销大。
- 文件写入磁盘, 要计算文件的起始位置, 文件数目 少的话, 这个开销就小了。
19. 数据库表里有 1 00 万条数据, 想要删除 80 万条数据, 但是因为锁的原因, 删除很慢, 现在想要快速删除怎么办 ?
如果需要保留的数据不多, 需要删除的数据很多, 那么可以考虑把需要保留的数据复制到临时表, 然后删除所有数据, 最后复制回去。 具体做法是: 先把要保留的数据用 insert into … select * from … where …移到另外的表中, truncate table 旧表, 然后再 insert into … select * from … , 这个不存在锁, 比 delete效率高。
20.常用SQL语句大全
- 创建表:CREATE TABLE <表名>(<列名> <数据类型>[列级完整性约束条件],......),例子:
-- 创建学生表
CREATE TABLE Student
(
Id INT NOT NULL UNIQUE PRIMARY KEY,
Name VARCHAR(20) NOT NULL,
Age INT NULL,
Gender VARCHAR(4) NULL
);
- 删除表:DROP TABLE <表名>;
- 清空表:TRUNCATE TABLE <表名>;
- 修改表:
-- 添加列 ALTER TABLE <表名> [ADD <新列名> <数据类型>[列级完整性约束条件]] -- 删除列 ALTER TABLE <表名> [DROP COLUMN <列名>] -- 修改列 ALTER TABLE <表名> [MODIFY COLUMN <列名> <数据类型> [列级完整性约束条件]] 例子: -- 添加学生表`Phone`列 ALTER TABLE Student ADD Phone VARCHAR(15) NULL; -- 删除学生表`Phone`列 ALTER TABLE Student DROP COLUMN Phone; -- 修改学生表`Phone`列 ALTER TABLE Student MODIFY Phone VARCHAR(13) NULL; - SQL查询:
SELECT [ALL|DISTINCT] <目标列表达式>[,<目标列表达式>]…
FROM <表名或视图名>[,<表名或视图名>]…
[WHERE <条件表达式>]
[GROUP BY <列名> [HAVING <条件表达式>]]
[ORDER BY <列名> [ASC|DESC]…]
例子:
SELECT * FROM Student
WHERE Id>10
GROUP BY Age HAVING AVG(Age) > 20
ORDER BY Id DESC
- SQL插入:
-- 插入不存在的数据
INSERT INTO <表名> [(字段名[,字段名]…)] VALUES (常量[,常量]…);
-- 将查询的数据插入到数据表中
INSERT INTO <表名> [(字段名[,字段名]…)] SELECT 查询语句;
例子:
-- 插入不存在的数据
INSERT INTO Student (Name,Age,Gender) VALUES ('Andy',30,'女');
-- 将查询的数据插入到数据表中
INSERT INTO Student (Name,Age,Gender)
SELECT Name,Age,Gender FROM Student_T WHERE Id >10;
- SQL更新:
UPDATE <表名> SET 列名=值表达式[,列名=值表达式…]
[WHERE 条件表达式]
例子:
-- 将Id在(10,100)的Age加1
UPDATE Student SET Age= Age+1 WHERE Id>10 AND Id<100
- SQL删除:DELETE FROM <表名> [WHERE 条件表达式]
- 创建索引:CREATE [UNIQUE] [CLUSTER] INDEX <索引名> ON <表名>(<列名>[<次序>][,<列名>[<次序>]]…);
- UNIQUE:表明此索引的每一个索引值只对应唯一的数据记录
- CLUSTER:表明建立的索引是聚集索引
- 次序:可选ASC(升序)或DESC(降序),默认ASC
-- 建立学生表索引:单一字段Id索引倒序
CREATE UNIQUE INDEX INDEX_SId ON Student (Id DESC);
-- 建立学生表索引:多个字段Id、Name索引倒序
CREATE UNIQUE INDEX INDEX_SId_SName ON Student (Id DESC,Name DESC);
- 删除索引:DROP INDEX <索引名>;
- 创建视图:
CREATE VIEW <视图名>
AS SELECT 查询子句
[WITH CHECK OPTION]
例子:
CREATE VIEW VIEW_Stu_Man
AS SELECT * FROM Student WHERE Gender = '男'
WITH CHECK OPTION
- 删除视图:DROP VIEW <视图名>;
